pylops_gpu.FirstDerivative¶
-
class
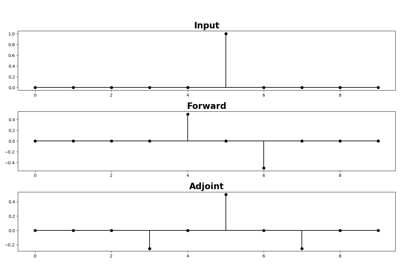
pylops_gpu.FirstDerivative(N, dims=None, dir=0, sampling=1.0, device='cpu', togpu=(False, False), tocpu=(False, False), dtype=torch.float32)[source]¶ First derivative.
Apply second-order centered first derivative.
Parameters: - N :
int Number of samples in model.
- dims :
tuple, optional Number of samples for each dimension (
Noneif only one dimension is available)- dir :
int, optional Direction along which smoothing is applied.
- sampling :
float, optional Sampling step
dx.- device :
str, optional Device to be used
- togpu :
tuple, optional Move model and data from cpu to gpu prior to applying
matvecandrmatvec, respectively (only whendevice='gpu')- tocpu :
tuple, optional Move data and model from gpu to cpu after applying
matvecandrmatvec, respectively (only whendevice='gpu')- dtype :
torch.dtypeornp.dtype, optional Type of elements in input array.
Notes
Refer to
pylops.basicoperators.FirstDerivativefor implementation details.Note that since the Torch implementation is based on a convolution with a compact filter \([0.5, 0., -0.5]\), edges are treated differently compared to the PyLops equivalent operator.
Attributes: Methods
__init__(N[, dims, dir, sampling, device, …])Initialize this LinearOperator. adjoint()Hermitian adjoint. apply_columns(cols)Apply subset of columns of operator cond([uselobpcg])Condition number of linear operator. conj()Complex conjugate operator div(y[, niter, tol])Solve the linear problem \(\mathbf{y}=\mathbf{A}\mathbf{x}\). dot(x)Matrix-vector multiplication. eigs([neigs, symmetric, niter, uselobpcg])Most significant eigenvalues of linear operator. matmat(X[, kfirst])Matrix-matrix multiplication. matvec(x)Matrix-vector multiplication. rmatmat(X[, kfirst])Adjoint matrix-matrix multiplication. rmatvec(x)Adjoint matrix-vector multiplication. todense([backend])Return dense matrix. toimag([forw, adj])Imag operator toreal([forw, adj])Real operator tosparse()Return sparse matrix. transpose()Transpose this linear operator. - N :